Text mining is a software technology that can help read unstructured texts. In other words, it recognizes grammatical structures of sentences, phrases and words and creates a kind of “fingerprint” from the source text as a result. Combined with conventional database indexing techniques, the comparison of text fingerprints delivers search and analysis methods that represent a paradigm shift for classical search-related activities.
While traditional search locates documents according to a user-entered keyword or combination of keywords, text mining allows the user to compare documents without entering any keyword(s) to identify documents that are related to the search document based on the fact that they contain similar language. This difference represents a complete change in thinking with regard to search, as explained below.
- The searcher no longer has to condense a topic into a few keywords, but can instead use an entire document as a query. Identifying keywords is in itself at cognitive operation, especially for a searcher without domain expertise. A document, on the other hand, contains many keywords and phrases and represents the subject of interest far more fully within its domain context, because the nature of language works like this.
- When a search is conducted based on the use of keywords, the results invariably include many false positives (i.e. documents that match the keyword but after some analysis turn out to be irrelevant to the subject). Text mining with a document fingerprint radically improves the contextualization of a document's content, thereby the results with far better relevance ranking. Simply because the ranking is based on many more parameters. The researcher generally abstracts keywords from the immediate context in which they appear. This is analogous to fishing in a large ocean with a very small net. When searching with a full document, the searcher does not limit his/her perspective conceptually – everything is context – and he/she fishes with the largest possible net. Another way of describing this: with text mining we fish with a representative pattern of many concepts rather than a few select, isolated concepts. This representative pattern is based on our unique document fingerprint format (see Figure 1 below).
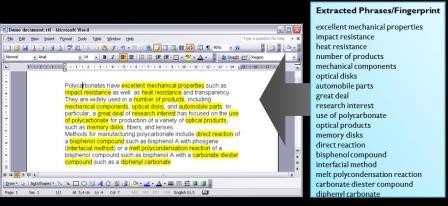
Figure 1: A document fingerprint
Text mining methods deliver new capabilities to knowledge workers:
They can use any document as a query to find familiar documents from any available source;
- They can use a document as an alert. If something new appears within the sources that might be relevant to that document, it can generate an alert or newsfeed for its owner; and
- Since a successful search no longer depends on having to formulate complex queries, domain experts can conduct the search activities themselves, without dependence on external search services.
We have developed a proprietary, patented text mining method that differs from other methods in that it does not require a taxonomy or lexical dictionary to generate a highly representative fingerprint from a document. Unlike most other methods, it needs neither complex statistical algorithms nor complex indexing. It is purely linguistic in nature using only grammatical processing and therefore covers a text completely, even if the text incorporates words or word combinations that are new to the world (neologisms).
White Spaces
Because of our use of text mining, the researcher can find “unused” terminology or ‘white spaces'. When the software compares a document with a large array of others, it calculates the number of hits for each source or filtered collection, showing which concepts have matches and which ones do not. Visibility of the zero scores allows for analysis and detection of areas of content that are very new, as well as areas in which one would still be relatively free to operate.